Building an Agentic RAG System for Enterprise Documents
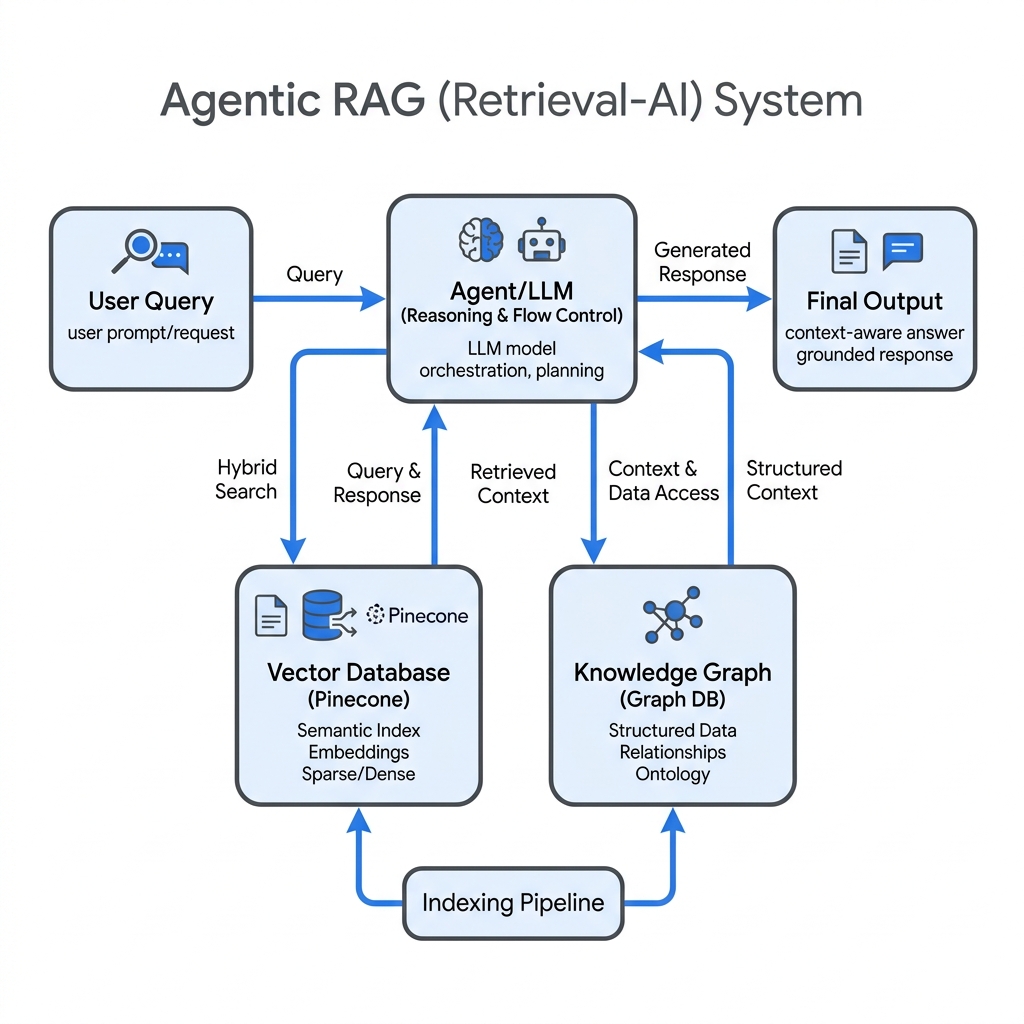
Retrieval-Augmented Generation (RAG) has become the standard for grounding Large Language Models (LLMs) in proprietary data. However, standard RAG pipelines often struggle with complex, multi-hop reasoning queries. To address this, I engineered an Agentic RAG System.
Unlike traditional linear retrieval, an Agentic approach empowers the LLM to act as a reasoning engine. It can dynamically decide what to search, when to use a vector database, and how to synthesize information from a Knowledge Graph.
The Power of Multi-Agent Collaboration
By dividing the cognitive load among specialized agents (e.g., a Document Retriever Agent, a Summarizer Agent, and a Code Generator Agent), the system achieves significantly higher accuracy. We utilized Pinecone for high-dimensional vector similarity search, enabling sub-millisecond retrieval across millions of text chunks.
Next Steps
The next iteration will focus on reducing inference latency by deploying smaller, fine-tuned embedding models on Modal serverless GPUs, mirroring the success of my previous bilingual speech-to-text project.